
TL;DR
We wired up a workflow that ingests Auto Manufacturer Packages—from Certificates of Origin to warranty claims and dealer incentives—and routes each file through the right Retab extractor.
The result: clean, validated JSON across critical documents in the automotive lifecycle.
This workflow is inspired by existing Retab clients in the automotive and manufacturing space who already run similar pipelines in production—reducing manual review, accelerating financing, and tightening compliance.
Perfect for:
OEMs & Tier-1 suppliers—cut manual processing of lease apps, KYC, and warranty claims
Dealers & Finance arms—accelerate onboarding and incentives reconciliation
Compliance & Ops teams—maintain audit-ready digital records with confidence scores
Why Auto packages are so complex
When an automaker (Audi, CNH, Bridgestone, etc.) or dealer group collects a package, it rarely comes as one file type. Instead, it’s a mix of:
Retail/lease applications (IDs, payslips, bank statements)
Income & KYC documentation
Dealer incentive submissions
Manufacturer’s Certificates of Origin
Warranty claim reconciliations
etc.
Each has its own structure, regulatory requirements, and downstream system dependency. Traditionally, staff re-key this data into DMS, ERP, or compliance systems—a slow, error-prone task.
How Retab Streamlines the Workflow
1. Classify Each Document
We first run documents through a classifier project trained on OEM packages on the Retab platform. It detects whether a file is a Certificate of Origin, Driver’s License, KYC document, etc.
clf_res = client.projects.extract(
project_id=CLASSIFIER_PROJECT_ID,
iteration_id=CLASSIFIER_ITERATION_ID,
document="certificate_origin.pdf",
)
label = clf_res.output["document_type"]2. Route to the Right Schema
Each label maps to a specialized extractor.
Certificate of Origin → Vehicle + dealer schema
Identification Document → Driver’s license schema, other related schemas
KYC/Income → Financial schema, other related schemas
Warranty claim → Warranty reconciliation schema
Dealer incentive → Incentive schema
etc.
3. Extract Structured Data
Retab parses the file into validated JSON with field-level confidence scores.
Example output from a Certificate of Origin:
{
"issue_date": "2017-10-20",
"certificate_number": "0188NO",
"manufacturer": {
"name": "TAIZHOU ZHONGNENG MOTORCYCLE CO., LTD",
"brand": "ZHNG"
},
"vehicle": {
"vin": "L5YTCKPA5G1156515",
"year": 2016,
"make": "ZHNG",
"model": "ZN150T-G",
"engine_power_hp": 8,
"engine_displacement_cc": 149
},
"dealer": {
"name": "COUNTYIMPORTS.COM",
"address_line": "1736 E. CHARLESTON BLVD #42",
"city": "LAS VEGAS",
"state_province": "NV"
},
"transfer_statement": {
"first_transfer_certified": true,
"authorized_representative_signature_present": true
}
}This isn’t brittle OCR: Retab enforces schemas, applies k-LLM consensus (you can read our blog-post about k-LLM here) for accuracy, and retains reasoning traces for auditability.
Step-by-step guide
Step #0 (Prep)—Data collection
Collect representative files of any doc type (PDF, images, scans) that you are used to process for work.
You’ll use 2–3 of them as seed examples.
Step #1—Define a Document-type classifier
Goal: given any file, return the most likely doc type (single label).
Create a project → in the prompt, write a short instruction for classification only (no field extraction).
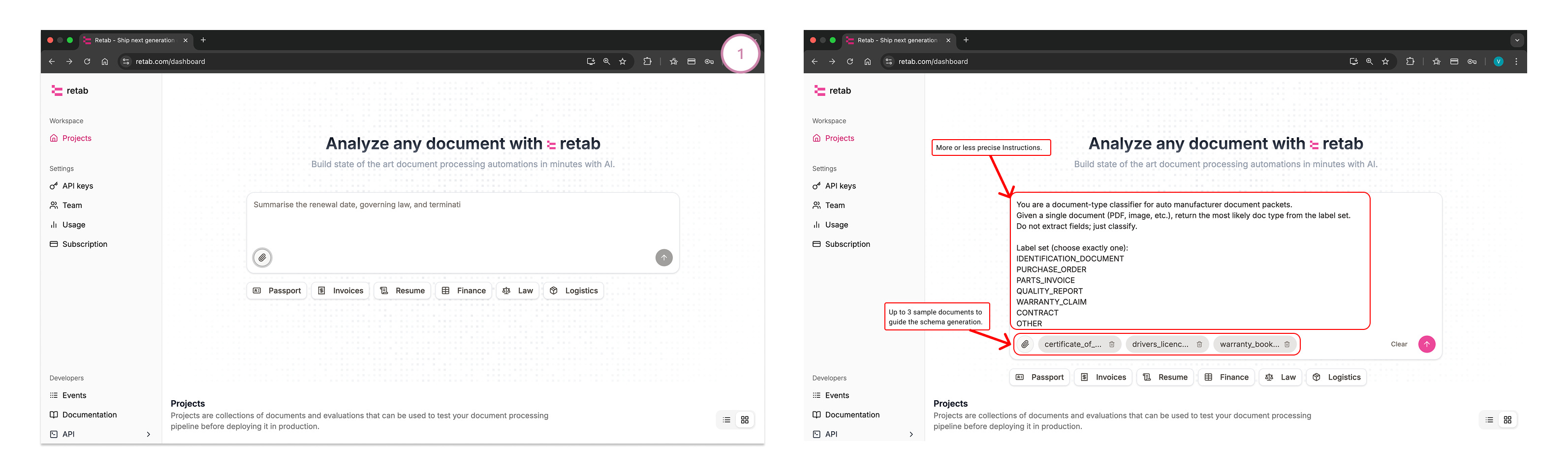
Example: “You are a classifier for auto manufacturer packets. Given one document, return exactly one label from: IDENTIFICATION_DOCUMENT, PURCHASE_ORDER, PARTS_INVOICE, QUALITY_REPORT, WARRANTY_CLAIM, CONTRACT, OTHER. Do not extract fields.”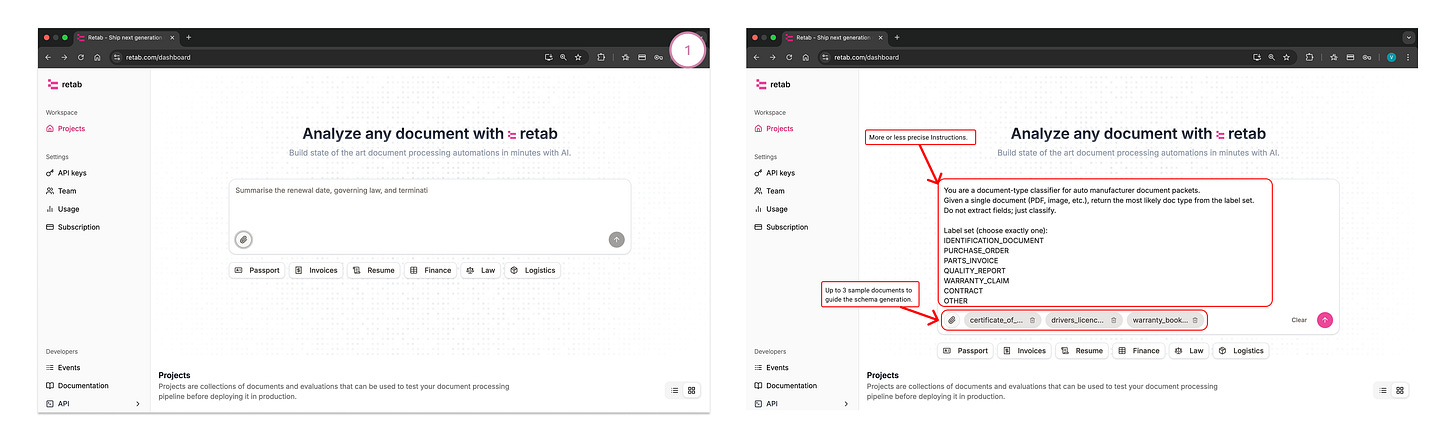
(Optional but handy) Define two fields in the schema:
Doc Type → single-select with your label list.
Confidence → number (0–100) to capture model certainty.
Add 2–3 seed documents (per the screenshots) and Run.
Retab generates the first iteration and fills the table (rows = docs, columns = Doc Type / Confidence).Review & correct low-confidence rows:
Click a cell to open the viewer and confirm the right label.
Save corrections → this becomes ground truth for evaluation.
Evaluate the classifier:
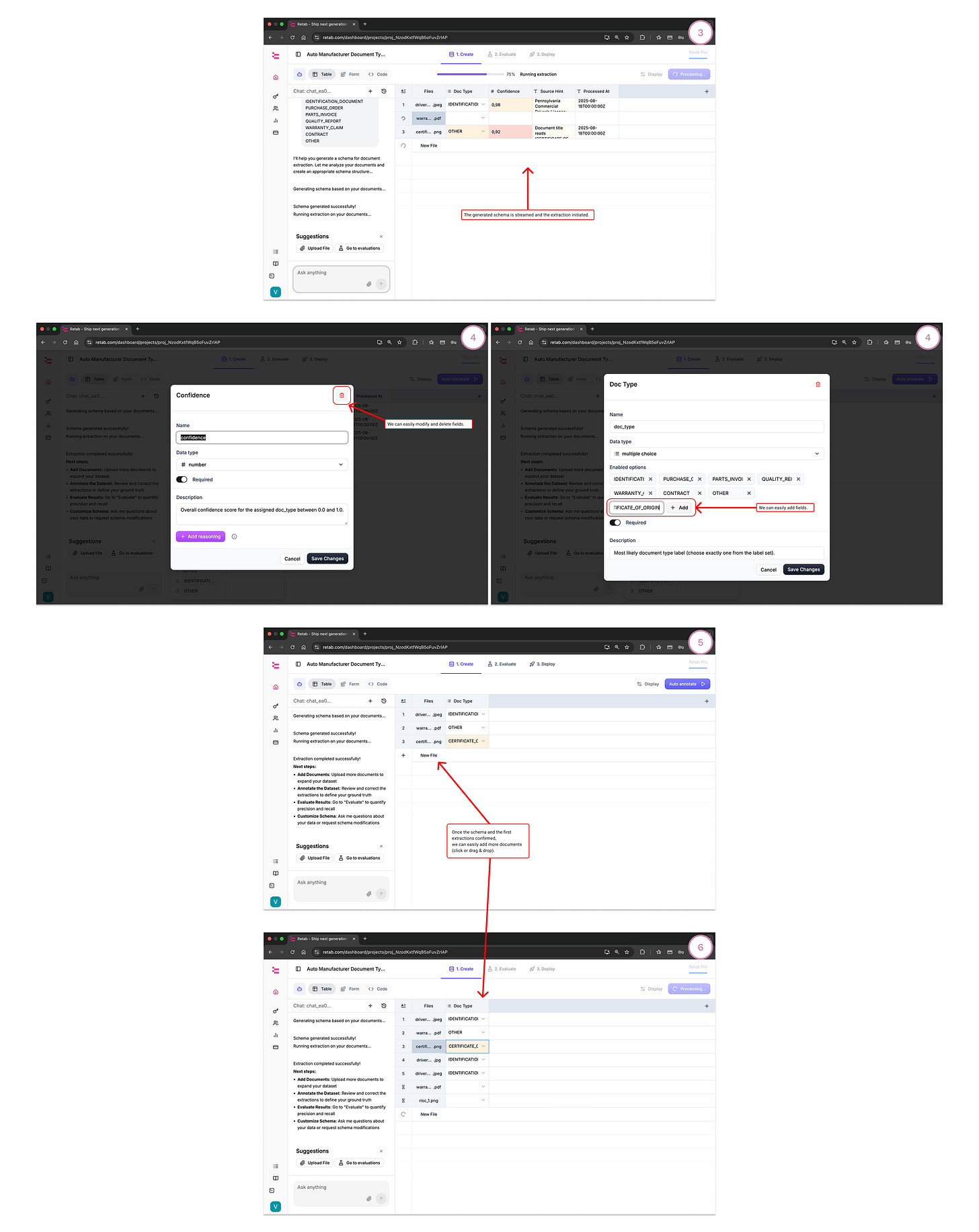
Check overall accuracy, per-label metrics, and error cases.
Iterate quickly (tighten label descriptions, add examples) until accuracy is stable.
Output of this step: a reliable classifier that assigns each incoming file to one label.
Step #2—Create Extraction schemas for each Label
Goal: for every doc type you care about, define the fields to extract.
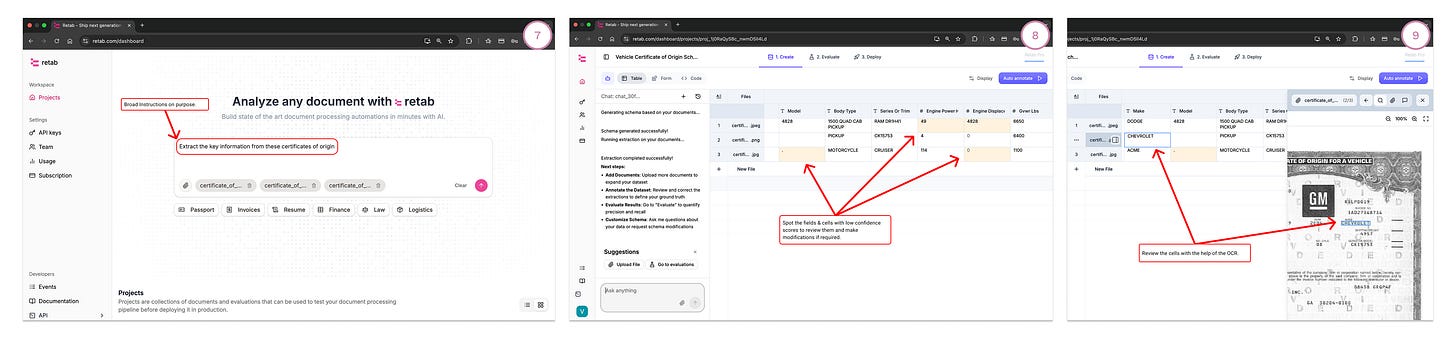
New project per doc type (e.g., Vehicle Certificate of Origin).
Write a broad instruction (“Extract the key fields from certificates of origin…”) and attach a few example documents.
Click Generate schema to get a first pass (Retab proposes fields).
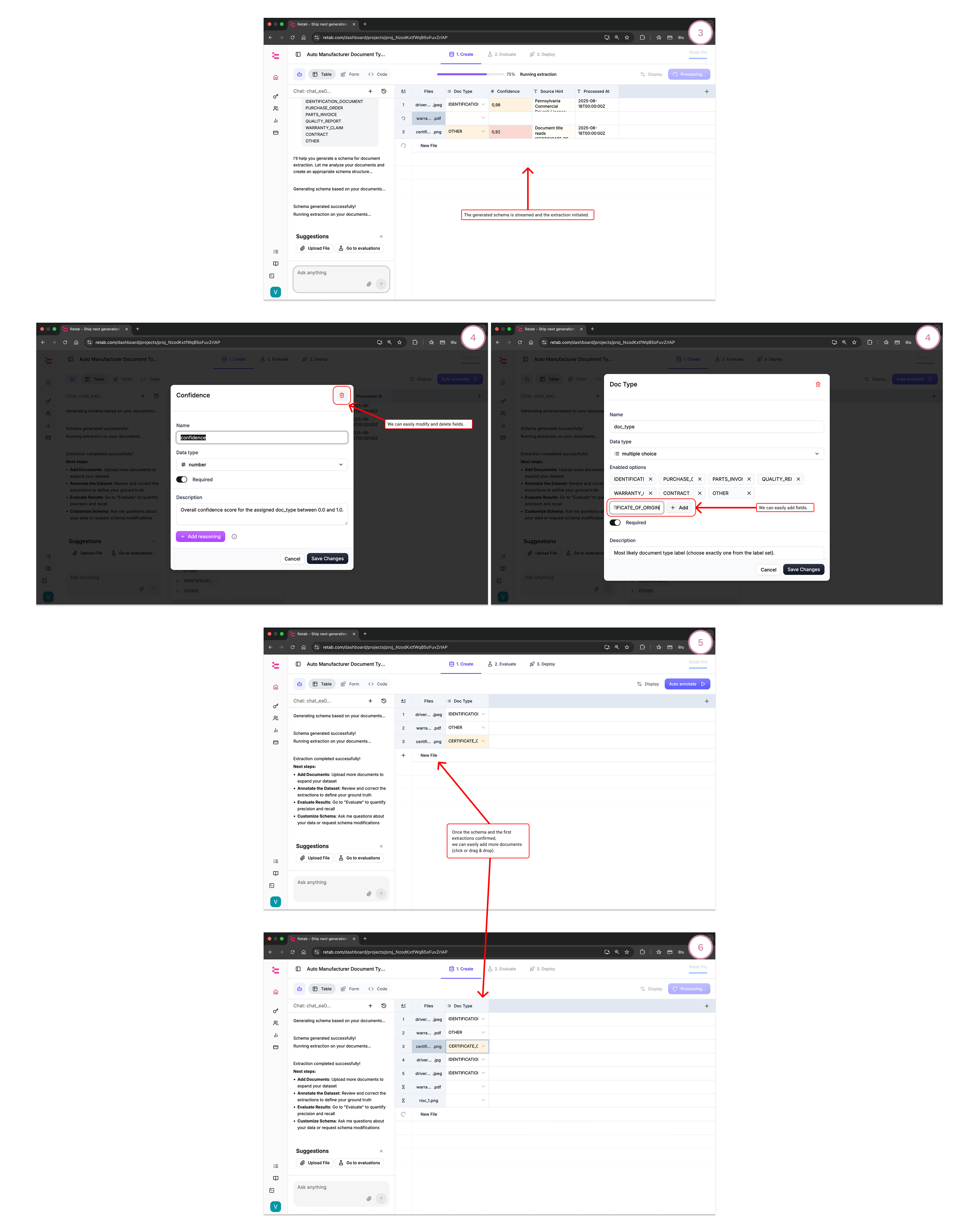
Refine fields:
Rename/add fields, write crisp descriptions, add constraints (regex, enums, formats, units).
For tricky fields, add a brief “how to reason” note.
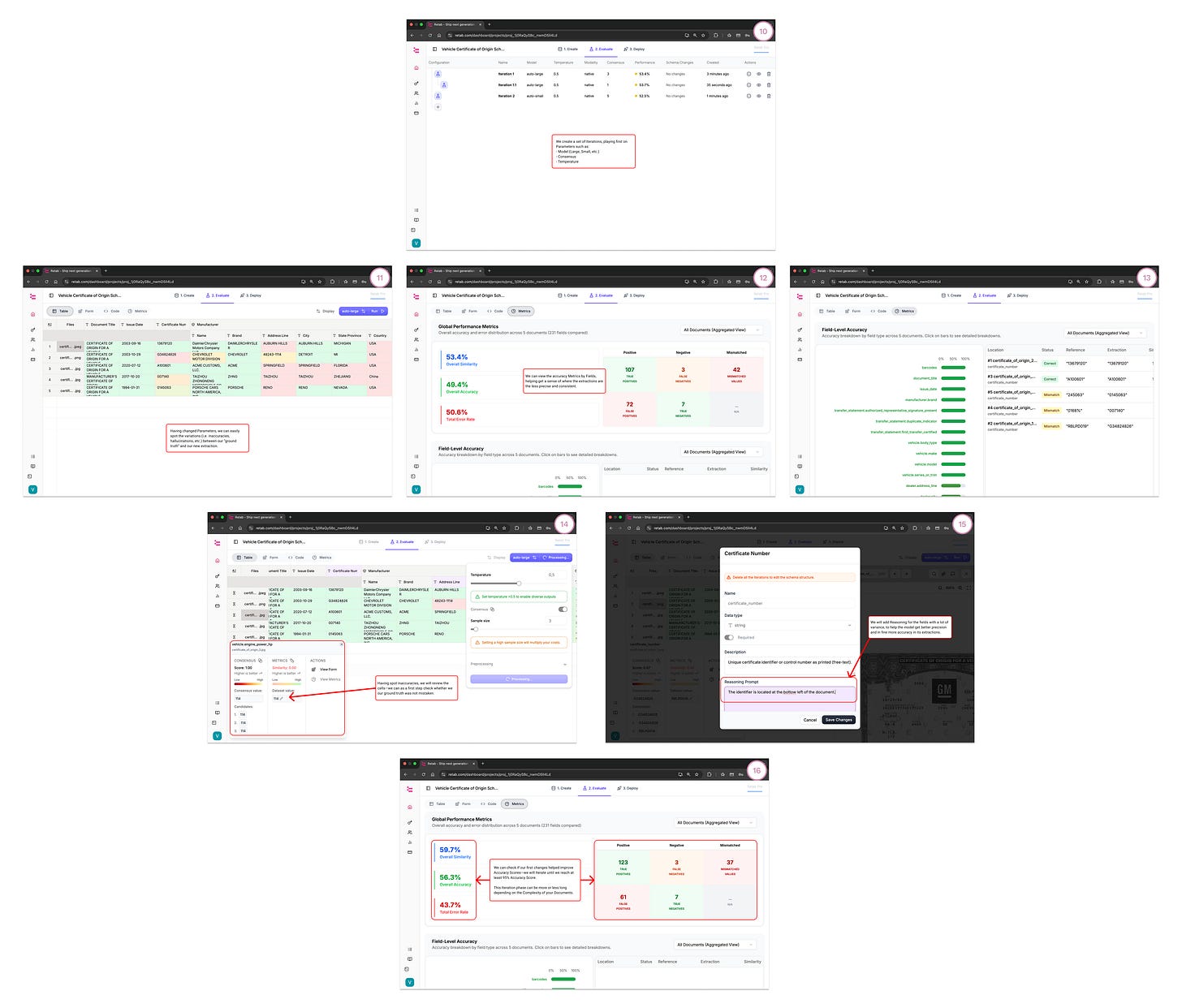
Bulk upload documents and Run:
Retab uses k-LLM consensus to fill the table.
Low-confidence cells are highlighted.
Review quickly:
Open the OCR/preview panel to validate values against the source.
Fix cells inline; those edits become ground truth.
Evaluate:
See doc-level accuracy, field-level accuracy, and the worst-offending fields.
Repeat: tweak field prompts/constraints → re-run → watch the metrics climb.
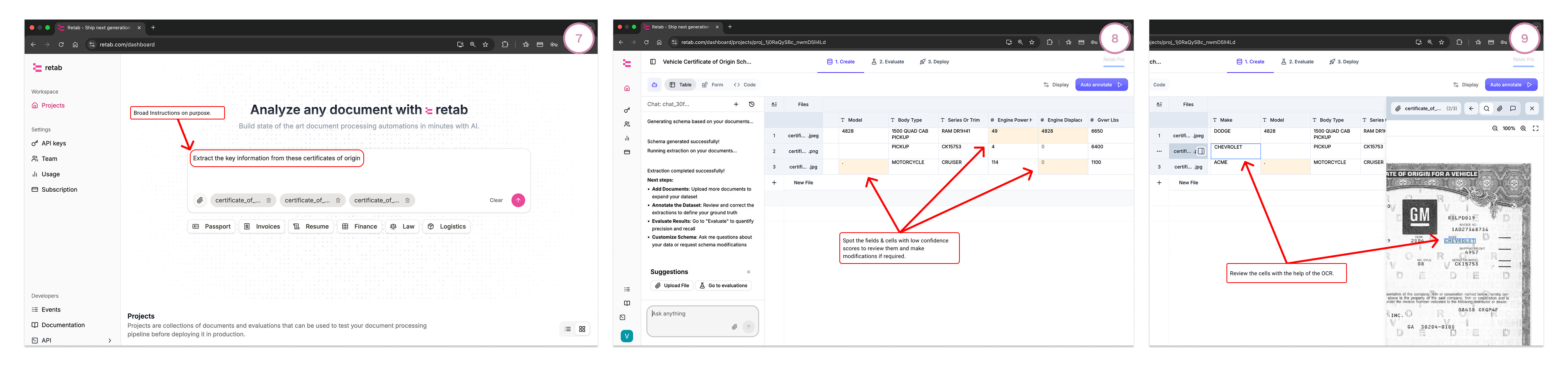
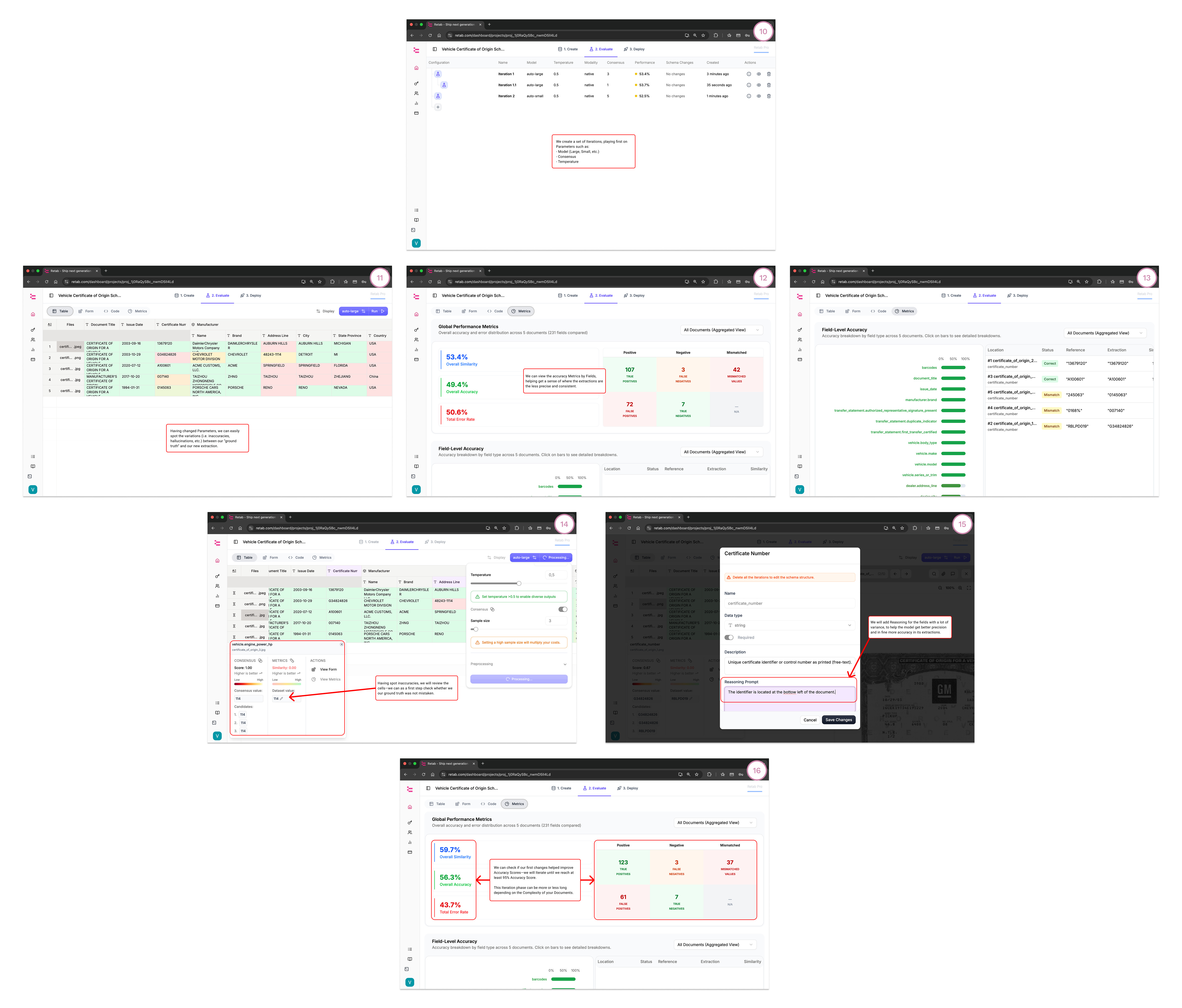
Output of this step: one production-ready schema per document type.
Step #3—Route: Classifier → Extractors
Create a simple routing map:
If Doc Type = CERTIFICATE_OF_ORIGIN → send to the Certificate of Origin extractor.
If Doc Type = WARRANTY_CLAIM → send to the Warranty Claim extractor.
…and so on.
(That mapping mirrors what’s shown in the screenshots: the classifier column feeds the right schema table.)
Step #4—Deploy
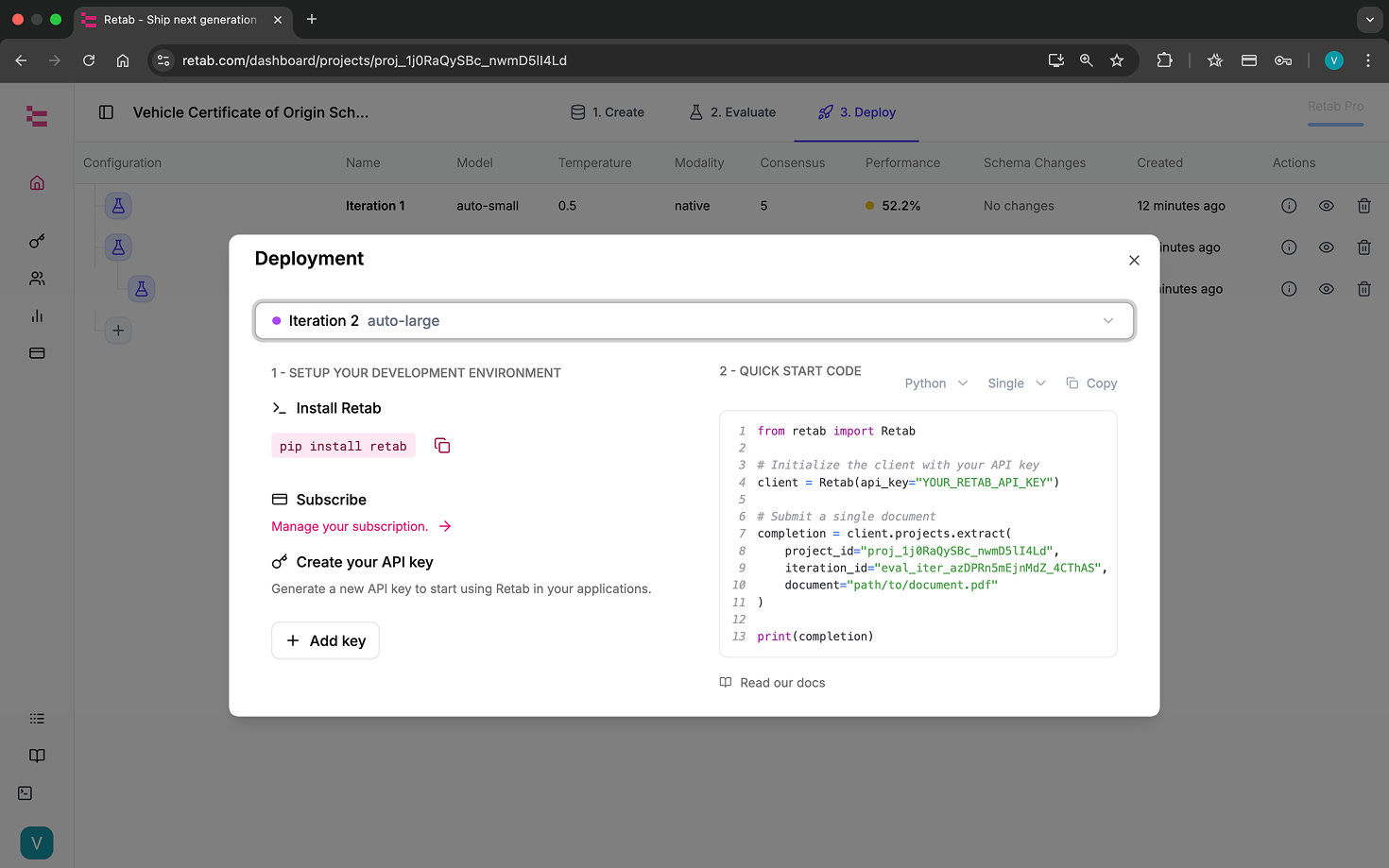
Plug your ingestion & delivery with your best Iteration:
Ingestion: API, forwarding email, Outlook plug-in, or shared drop link.
Delivery: Google Sheets / Excel, Webhook to your app, or your data store.
Flip Deploy, and your pipeline is live:
files arrive
→ get classified
→ flow to the right extractor
→ structured data is sent downstream
Step #5—Monitor & Improve
Track volumes, accuracy, and low-confidence hot-spots.
Add new examples or adjust a field’s description when you see drift.
Retab continuously selects strong models; you keep the final say via evals.
Why Retab works well here
Schema enforcement → ensure every VIN, certificate number, and date is validated
Confidence scoring → route low-confidence extractions to manual review before compliance risk arises
Consensus layer → boost accuracy by merging multiple LLM outputs
Auditability → reasoning + source highlighting makes reconciliations regulator-ready
Closing thoughts
Automotive OEMs and dealer networks handle thousands of documents per vehicle lifecycle. Every missed VIN digit or KYC mismatch means delays in financing, warranty reimbursement, or dealer incentives.
By plugging Retab into the ingestion flow, manufacturers can:
Eliminate repetitive data entry
Accelerate retail and dealer processes
Maintain transparent, audit-ready digital trails across jurisdictions
This workflow mirrors what existing Retab clients are already running in production—proof that document automation in manufacturing is no longer experimental, but a competitive necessity.
If you want to try the pipeline or adapt it to your use-case, check our Platform, Documentation and the related Notebook on GitHub.
Don't hesitate to reach out on X or Discord if you have any questions or feedback!